
성취기준 코드 분류 벤치마크 KorEduBench 제작기
Published:
Motivation
KorEduBench는 황승원 교수님의 “자연언어처리 개론” 강의의 과제로 진행한 프로젝트입니다.
해당 프로젝트를 시작한 계기는, ‘한국 공교육에는 왜 아직 LLM이 자리잡지 못했을까?’라는 질문이었습니다.
가볍게 생각해보면 몇 가지 이유를 떠올릴 수 있었습니다.
- 한국어가 LLM에게 low-resource language 인 것
- 한국의 공교육에 대한 데이터 역시 low-resource
한국 공교육에 LLM을 도입한다면 다양한 방면에서 사용할 수 있을 겁니다.
- 어떤 텍스트(문제)와 연계된 교육과정의 탐색
- 학생의 부족한 학습내용을 진단하여 도움을 주는, 진단형 피드백
- 학생의 수준을 실시간으로 확인해주는, 맞춤형 학생 평가
그러나 공교육에 LLM을 사용하기 위한 연구는 찾기 어려웠습니다. 이에 LLM이 현재 공교육에 사용한다면 어느정도 성취를 보일 수 있는지 진단하기 위한 벤치마크가 필요하다고 생각했습니다. 벤치마크를 제작하고, 몇가지 LLM에 대해 성취를 확인하여 현재 LLM이 공교육 도메인에서 어떤 성능을 보이는지 확인하고자 했습니다.
Problem Definition
가장 기본적이고, 기준으로 삼을만한 task는 ‘어떤 text를 특정 교육과정의 성취기준으로 분류’하는 task라고 생각했습니다. 만약,
“우리는 어떤 공동체의 일원으로서 우리의 말과 행동이 어떻게 다른 사람에게 영향을 미치는지 성찰해야 합니다.”
라는 텍스트가 있다면,
“10국01-06; 언어 공동체의 담화 관습을 성찰하고 바람직한 의사소통 문화 발전에 기여하는 태도를 지닌다”
라는 성취기준을 분류해내는 task입니다. 예시에서는 가시성을 위해 성취기준의 코드와, 그것에 해당하는 content를 모두 담았지만, code만 분류하더라도 충분할 겁니다.
교육 도메인의 text를 특정 성취기준으로 분류할 수 있어야, 관련한 내용을 탐색하고, 부족한 내용을 확인하는 등의 후속 작업이 가능할 것 입니다.
그렇기에 벤치마크의 task는 “Text-to-Achievement_Standards_code”로 제한하고, 아래의 4개의 Key Question을 만들었습니다.
- How well LLMs classify texts without fine-tuning?
- Does few-shot prompting significantly improve performance?
- How much does accuracy change with increasing model size?
- Can smaller, fine-tuned models achieve similar results efficiently?
전국의 학생들이 모두가 혜택을 받는 LLM이라면 요청 횟수는 상당히 많을 것입니다. 이러한 비용을 국가에서 감당하기 위해선, 작은 모델에서 교육 도메인에 대한 fine-tuning을 했을때 효율이 높아야 한다고 생각했습니다.
이에 따라, 위의 4가지 Key Question에 대한 실험을 진행하며 그 가능성을 확인해 보고자 하였습니다.
Experiments Design
Dataset
데이터셋은 AI Hub에서 가져올 수 있었습니다.
AI Hub에서 “교과 단계별 교과데이터”를 제공하고 있었는데, 해당 데이터에는 교과서나 문제집에 담겨있는 텍스트와 그것에 대한 성취기준 라벨링이 json으로 준비되어있었습니다. 성취기준은 2009, 2015, 2022로 나누어 준비되어있었고, 그중에서 가장 최신인 2022를 기준으로 작업을 준비하였습니다.
전처리 단계에서 다양한 시행착오를 할 수 잇었습니다. 해당 데이터셋 자체에 꽤나 문제가 있어서, 2022년 성취기준 라벨에 2022년에는 존재하지 않는 2009년의 성취기준과 코드가 적혀있다거나, 특정 과목/성취기준에 해당하는 text가 너무 적어 불균등함에 문제가 있는 등의 상황을 확인했습니다.
지속적인 필터링과 모니터링 단계를 팀원들과 진행하며 잘못된 라벨 없이, 지나친 불균등함이 없는 데이터셋을 완성할 수 있었습니다.
Pipeline
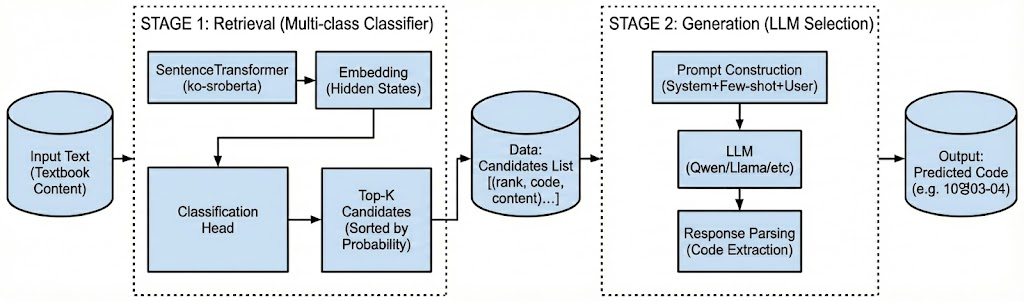
파이프라인은 위의 사진과 같이 준비하였습니다.
초기에는 Retrieval 없이 모든 성취기준을 LLM에 input으로 넣는 것을 생각하였습니다. 그러나 실제로 진행해본 결과, 지나치게 많은 데이터 양으로 인해, 정확도나 비용에서 문제가 발생한다고 판단하였습니다. 그래서 이를 해결하기 위해 다른 tool을 연결해서 top-k를 찾는 것이 좋겠다고 판단하였고, 해당 tool은 Multi-class Classifier인 RoBERTa-large를 finetuning 하여 제작하였습니다.
해당 tool을 이용하는 방법 역시 논의가 있었습니다. ReAct와 같은 외부 agent calling system과 유사하게 LLM이 top-k classifier(RoBERTa)에 넣을 input을 결정하여 classifier를 실행하고 그 결과로 다시 LLM을 실행하는, ‘text -> LLM -> top-k -> LLM’ 의 2-step 방식을 고려하였습니다.
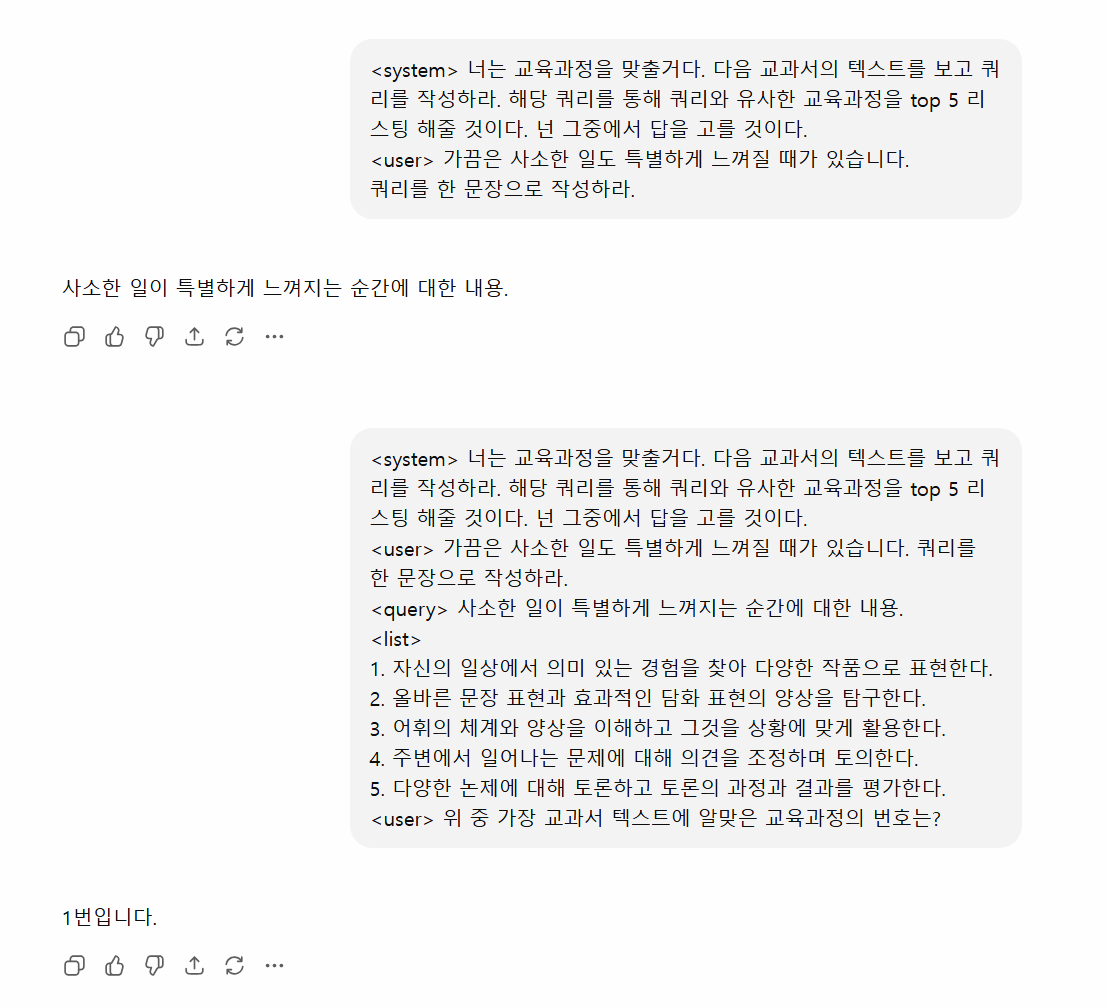
LLM이 text에서 교육과정 top-k 선별에 필요한 중요한 내용을 잘 필터링 할 것이라는 기대가 있었기 때문입니다.
그러나 몇가지 문제가 있었습니다.
- LLM이 새로 만드는 문장이 rawtext와 크게 다르지는 않다
- RoBERTa를 raw text를 기준으로 학습시켰다
RoBERTa를 raw text가 아닌, 특정 LLM의 답변을 기준으로 학습시킬 수도 있으나, Qwen으로 학습한 RoBERTa를 Llama에 적용시키는 것도 불편하고, 그렇다고 모든 모델에 대해 매번 RoBERTa를 학습시키는 것도 상당한 비용이 드는 일이었기에 단순화 하여 [그림 1]과 같이 raw text를 바로 RoBERTa에 넣는 RAG 형식으로 자리잡았습니다.
Experiments Result
1. How accurate are LLMs in classifying texts by subject?
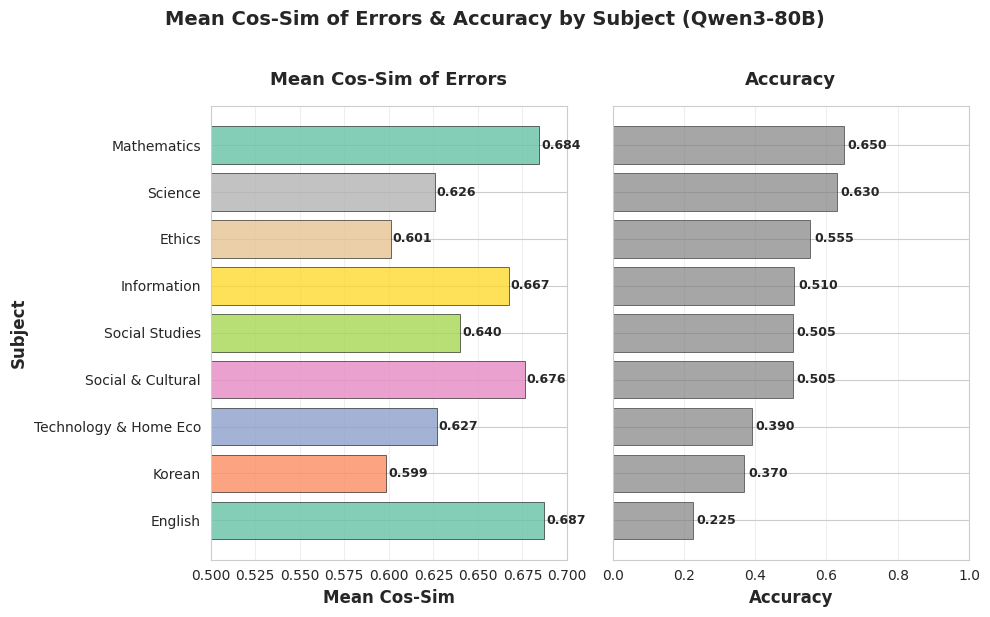
과학, 수학에서 높은 성적을 보이고, 영어에서 약한 모습을 보였습니다.
과학이나 수학에서 높은 성적을 보인 것은, pretrain에 수과학 내용이 많은 것과, 해당 과목의 교재 텍스트가 분류가 쉽게 특징이 잘 나타나서 일 것으로 생각하였습니다.
그에 반해, 영어는 교재 텍스트 자체가 특징이 크게 나타나지 않았고, 학습목표도 명확하게 분리되지 않았습니다.
추가적인 에러 분석을 위해 input으로 들어간 텍스트와, LLM이 예측한 학습목표간의 cos-sim을 확인하였습니다. 그 결과 예상대로 영어과목 오답의 cos-sim이 매우 높은 것을 확인할 수 있었습니다. 비록 오답이긴 하지만, 정답과 유사한 답변을 LLM이 제출했다는 것으로 해석할 수 있고, 실제로 직접 샘플링하여 제가 확인했을 때도 그러한 경향이 느껴졌습니다.
2. Does few-shot learning improve accuracy?
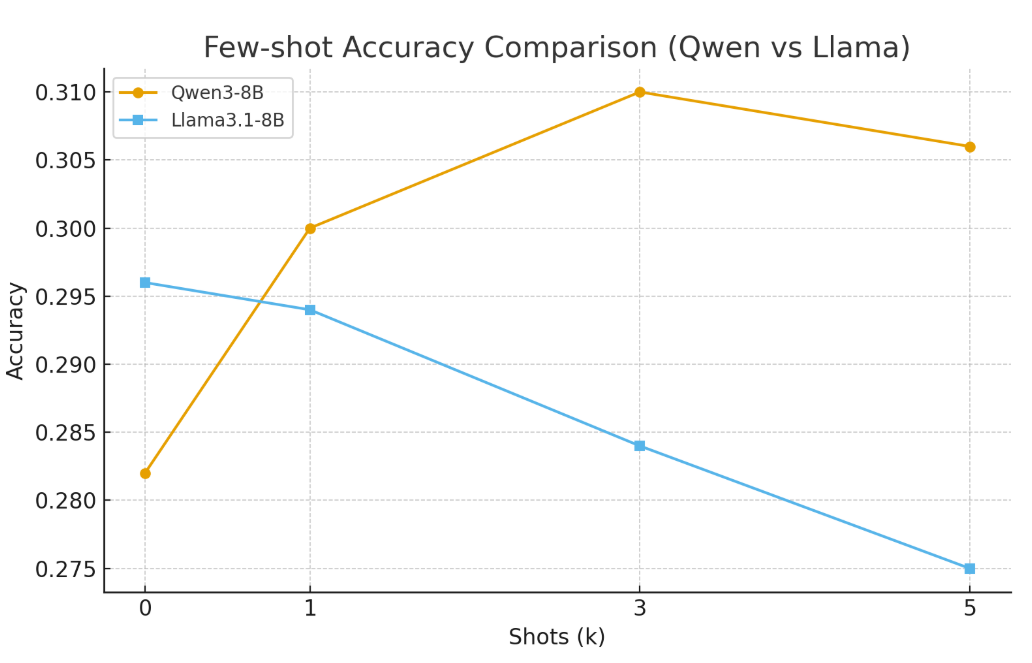
Qwen에서는 0-shot 에서 3-shot 까지 올릴때 정확도 향상이 있었으나, Llama는 오히려 감소하는 경향을 보였습니다. 그리고, Qwen에서 보인 정확도 향상 역시 그다지 큰 폭이 아니었기에 다른 부분에서 향상이 없었는지 추가 분석을 진행하였습니다.
추가 분석 결과, few-shot은 정확도의 향상보다는, “존재하지 않는 invalid 학습목표 코드”를 제출하는 케이스의 감소에 큰 영향을 주었습니다. 그렇다면, few-shot은 추가적인 fine-tuning과 같이 사용한다면 시너지가 생길 것을 기대하였습니다. (검증은 진행하지 못하였습니다)
3. How much does accuracy change with increasing model size?
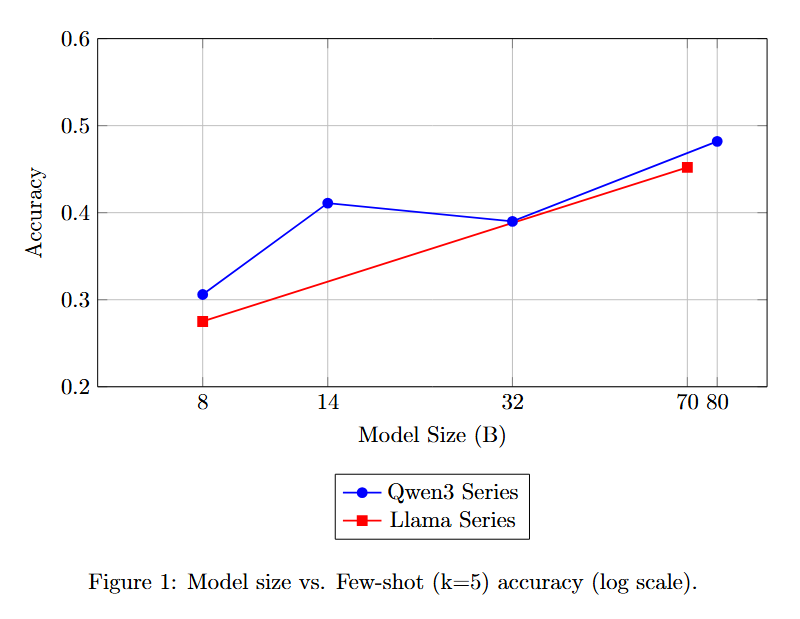
8B에서 80B 가량으로 모델 크기를 늘리며 정확도가 30% 정도에서 48% 정도까지 상승함을 확인했습니다. 비용이 커지긴 하지만, 모델 사이즈를 키우는 것이 가장 효과적이었습니다.
4. Can small fine-tuned models match large few-shot LLMs?
Fine tuning을 하면 7B의 모델로 70B 모델이나 GPT-4.1-mini 이상의 정확도까지 끌어올릴 수 있었습니다. (4번의 실험을 제외하면 모두 FT 하지 않은 모델로 실험을 진행하였습니다)
그러나 세부적으로 분석해보니, FT 모델은 다른 큰 사이즈의 모델에 비해 invalid (존재하지 않는 코드) 답변이 많았음을 확인할 수 있었습니다. 모델 사이즈를 늘리는 대신 FT를 중점적으로 사용하는 것은 Robustness 를 낮출 수 있다는 trade-off를 확인할 수 있었습니다.
Conclusion
피드백을 받을 시간이 없었던 관계로, 저희가 발견하지 못한 여러 부족한 점이 있었을 것이라 생각합니다. 아무래도 개인 컴퓨터와, 사비로 api를 구매해 사용하며 사용한 모델이 지나치게 성능이 낮았을 수 있다는 문제점도 있었습니다. 데이터셋도 그리 좋은 품질이 아니었다는 점이 한계로 작용했을 것 같습니다
그럼에도 다음과 같은 결론을 내려볼 수 있었습니다.
Can AI be used in education alignment?
수학과 과학에서는 꽤나 높은 성능을 보였습니다. 그러나 아직 80B 정도의 모델로는 실업에서 곧바로 사용하기에 부족할 수 있으며, 많은 추가적인 fine-tuning 과정이 필요할 것으로 생각합니다. 특히, 다른 과목에서 사용할 때는 더욱 주의해야할 것입니다.What needs to improve for reliable classroom use?
분류가 모호한 텍스트에 대한 처리를 고민해야할 것이고, 거의 구분이 어려운 교육목표들에 대해서는 어느정도 그룹으로 묶어서 처리할 수 있도록 해야하지 않을까 생각하였습니다.How can we evaluate future models for educational use?
우리의 벤치마크가 공교육의 LLM의 성능 측정에 유용하게 사용할 수 있지 않을까 생각합니다.
많이 헤메고, 다시 새로 작업하기도 하며 많은 시행착오가 있었습니다. 그렇지만 팀원들 모두 자기 역할을 잘 해내주고, 결국 2개월의 과정속에서 나름 의미있는 결론을 내며 (결론이 안 나는게 제일 무서웠습니다) 마무리를 지을 수 있었던듯 하여 꽤나 보람을 느낄 수 있었습니다.